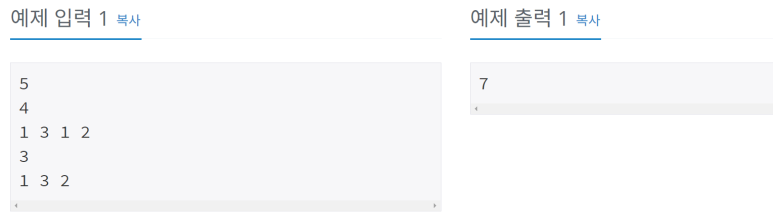
[문제]
동호와 규완이는 212호에서 문자열에 대해 공부하고 있다. 김진영 조교는 동호와 규완이에게 특별 과제를 주었다. 특별 과제는 특별한 문자열로 이루어 진 사전을 만드는 것이다. 사전에 수록되어 있는 모든 문자열은 N개의 "a"와 M개의 "z"로 이루어져 있다. 그리고 다른 문자는 없다. 사전에는 알파벳 순서대로 수록되어 있다.
규완이는 사전을 완성했지만, 동호는 사전을 완성하지 못했다. 동호는 자신의 과제를 끝내기 위해서 규완이의 사전을 몰래 참조하기로 했다. 동호는 규완이가 자리를 비운 사이에 몰래 사전을 보려고 하기 때문에, 문자열 하나만 찾을 여유밖에 없다.
N과 M이 주어졌을 때, 규완이의 사전에서 K번째 문자열이 무엇인지 구하는 프로그램을 작성하시오.
[입력]
첫째 줄에 N, M, K가 순서대로 주어진다. N과 M은 100보다 작거나 같은 자연수이고, K는 1,000,000,000보다 작거나 같은 자연수이다.
[출력]
첫째 줄에 규완이의 사전에서 K번째 문자열을 출력한다. 만약 규완이의 사전에 수록되어 있는 문자열의 개수가 K보다 작으면 -1을 출력한다.
[예제]

>문제 풀이
N개의 "a"와 M개의 "z"으로 만들수 있는 문자열을 사전순으로 정렬했을 때 K번째 문자열을 구하라.
N과 M이 100 이하의 자연수이므로 N과 M으로 조합 가능한 문자는 (200!)/(100!*100!) 개 이다.
즉, 이걸 하나씩 다 조합해보고 k번째 문자열을 구하기에는 시간도 메모리도 너무 비효율적이다.
그럼 어떻게 풀어야 할까?
사전순으로 a가 먼저이고 z가 다음이다. 즉, 조합할 때 순서가 있다는 것.
만약 a 3개와 z 3개로 만들 수 있는 문자열에 대해서 살펴본다고 했을 때
맨 앞글자가 a로 시작 + "a 2개와 z 3개로 만들 수 있는 문자열"
맨 앞글자가 z로 시작 + "a 3개와 z 2개로 만들 수 있는 문자열"
이렇게 될 것이다.
즉, dp[N][M]를 "a" N개와 "z" M개로 만들 수 있는 문자열의 개수 라고 할 때
dp[N][M]= dp[N-1][M] + dp[N][M-1] 의 점화식을 만들 수 있다.
** 여기까지는 금방 생각해 냈는데, 구현에서 막혔다.**
그래서 다른 분의 코드를 참고하였다.
[알고리즘] - 백준 1256번 : 사전(JAVA)
문제 풀러가기dp 문제를 풀이하는 방식으로 접근을 하여야 하지만, 좀 더 알아야 할 것이 있었습니다!n개의 문자와 m개의 문자를 조합하여 만들 수 있는 문자열의 개수를 구할 수 있는 것이 시급
velog.io
먼저 함수를 두 가지로 나눈다.
check 함수와 makeS함수
함수 1) check(int a, int z) //a는 "a"의 개수, z: "z"의 개수
"a" a개와 "z" z개로 만들 수 있는 문자열 개수를 구하는 함수이다.
함수 2) makeS(int a, int z, int k) //k는 구하고자하는 문자열의 순서
"a" a개와 "z" z개로 만들수 있는 문자열들 중 k번째 문자열을 구하는 함수
<main>
//"a" N개와 "z" M개로 만들 수 있는 문자열의 개수가 K보다 작으면 -1출력
if( check(N, M) < K ) 일 때 -1출력
else{
makeS(N, M, K);
문자열 출력;
}
check 함수는 점화식을 그대로 구현한 것이라 아래 코드를 보면 어렵지 않은 것을 알 수 있다.
makeS 함수도 어렵지는 않다.
(* 문자는 하나씩("a"||"z") 붙여줘야 하기 때문에 StringBuilder를 사용했다.)
분기점 1)
a==0일 때는 남은 a가 없으니까 뒤로는 z로만 채우면 되고
z==0일 때는 남은 z가 없으니까 뒤로는 a로만 채우면 된다.
분기점 2)
// a로 시작하게 됐을 때 만들 수 있는 문자열의 개수를 구해본다.
double check= check(a-1, z);
if ( check < k ) {
// 이면, a로 시작하게 되면 k번째 문자열을 포함하는 문자열을 못만든다는 것이다.
// 그러면 "z"를 붙여줘야하고
// makeS(a, z-1, k-check);
// 왜?? a는 안썼고, z는 하나 썼으며
// k에서 check를 빼주는 이유: z로 시작함으로써 a로 시작하는 문자열들의 개수는 빼고 넘겨주는 것
}else{
// check>=k 이면, a로 시작했을 때 k번째 문자열을 구할 수 있다.
// "a"를 붙여주고
// makeS(a-1, z, k);
// 왜?? a 하나 썼고, z는 안썼다.
//그리고 a로 시작 했을 때 k번째 문자열을 구할 수 있으니까 그대로 넘겨준다.
}
>전체 코드
import java.util.Scanner;
public class Main {
static double[][] dp= new double[101][101];
static StringBuilder sb= new StringBuilder();
public static void main(String[] args) {
Scanner scan= new Scanner(System.in);
//N은 a개수, M은 z개수, K번째 문자열을 구해야함.
//N, M은 100이하, K는 10억 이하의 수
int N= scan.nextInt();
int M= scan.nextInt();
double K= scan.nextDouble();
if(check(N, M)<K) {
System.out.println("-1");
}else {
makeS(N, M, K);
System.out.println(sb.toString());
}
}//main
//개수 구하는 함수
public static double check(int a, int z) {
if(a==0||z==0) return 1;
if(dp[a][z]!=0) return dp[a][z];
return dp[a][z]= Double.min(check(a-1, z)+check(a, z-1), 1000000001);
}
//문자열 만드는 함수
public static void makeS(int a, int z, double k) {
if(a==0) {
for(int i=0; i<z; i++)
sb.append("z");
return;
}
if(z==0) {
for(int i=0; i<a; i++)
sb.append("a");
return;
}
double check= check(a-1, z);
if(k>check) {
sb.append("z");
makeS(a, z-1, k-check);
}else {
sb.append("a");
makeS(a-1, z, k);
}
}//makeS
}https://www.acmicpc.net/problem/1256
1256번: 사전
첫째 줄에 N, M, K가 순서대로 주어진다. N과 M은 100보다 작거나 같은 자연수이고, K는 1,000,000,000보다 작거나 같은 자연수이다.
www.acmicpc.net
'알고리즘 > 백준 알고리즘' 카테고리의 다른 글
| [백준 알고리즘]1735번: 분수 합_Java (1) | 2021.10.26 |
|---|---|
| [백준 알고리즘] 3955번: 캔디 분배_Java (0) | 2021.10.26 |
| [백준 알고리즘]2143번: 두 배열의 합_Java (0) | 2021.10.03 |
| [백준 알고리즘]2243번: 사탕상자_Java (0) | 2021.10.03 |
| [백준 알고리즘]1072번: 게임_Java (0) | 2021.09.30 |